
AnythingLLM:基于RAG方案构专属私有知识库(开源|高效|可定制)
AnythingLLM:基于RAG方案构专属私有知识库(开源|高效|可定制)一、前言
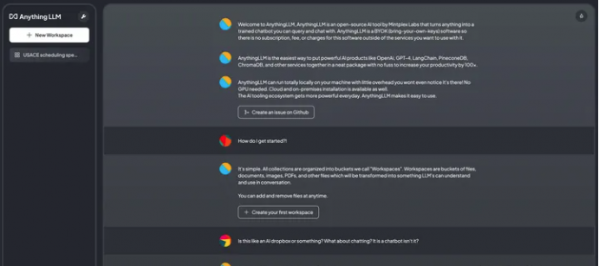
二、概述2.1、AnythingLLM 介绍
2.2、AnythingLLM 特点
- 多用户支持和权限管理:允许多个用户同时使用,并可设置不同的权限。
- 支持多种文档类型:包括 PDF、TXT、DOCX 等。
- 简易的文档管理界面:通过用户界面管理向量数据库中的文档。
- 两种聊天模式:对话模式保留之前的问题和回答,查询模式则是简单的针对文档的问答
- 聊天中的引用标注:链接到原始文档源和文本。
- 简单的技术栈,便于快速迭代。
- 100% 云部署就绪。
- “自带LLM”模式:可以选择使用商业或开源的 LLM。
- 高效的成本节约措施:对于大型文档,只需嵌入一次,比其他文档聊天机器人解决方案节省 90% 的成本。
- 完整的开发者 API:支持自定义集成。
2.3、支持的 LLM、嵌入模型和向量数据库
- LLM:包括任何开源的 llama.cpp 兼容模型、OpenAI、Azure OpenAI、Anthropic ClaudeV2、LM Studio 和 LocalAi。
- 嵌入模型:AnythingLLM 原生嵌入器、OpenAI、Azure OpenAI、LM Studio 和 LocalAi。
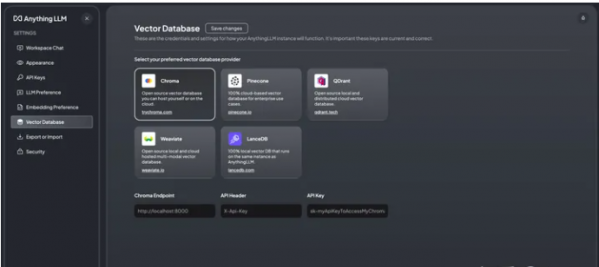
- 向量数据库:LanceDB(默认)、Pinecone、Chroma、Weaviate 和 QDrant。
2.4、技术概览
- collector:Python 工具,可快速将在线资源或本地文档转换为 LLM 可用格式。
- frontend:ViteJS + React 前端,用于创建和管理 LLM 可使用的所有内容。
- server:NodeJS + Express 服务器,处理所有向量数据库管理和 LLM 交互。
三、AnythingLLM 部署
3.1、安装 Chroma Vectorstore
- git clone https://github.com/chroma-core/chroma.git
- cd chroma
- docker compose up -d –build
[color=rgb(51, 102, 153) !important]复制代码
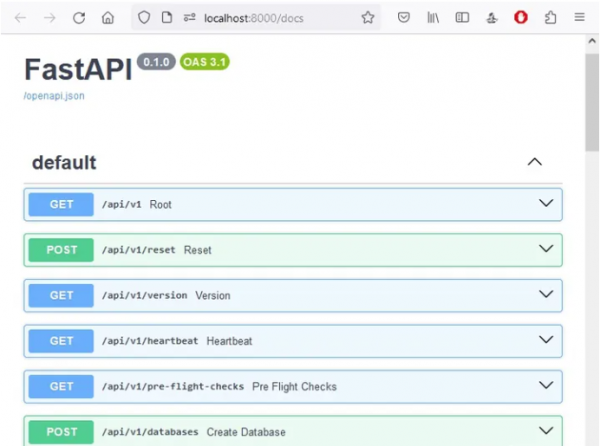
- curl -X ‘POST’ ‘http://localhost:8000/api/v1/collections?tenant=default_tenant&database=default_database’
- -H ‘accept: application/json’
- -H ‘Content-Type: application/json’
- -d ‘{ “name”: “playground”, “get_or_create”: false}’
[color=rgb(51, 102, 153) !important]复制代码
- curl http://localhost:8000/api/v1/collections
- [
- {
- “name”: “playground”,
- “id”: “0072058d-9a5b-4b96-8693-c314657365c6”,
- “metadata”: {
- “hnsw:space”: “cosine”
- },
- “tenant”: “default_tenant”,
- “database”: “default_database”
- }
- ]
[color=rgb(51, 102, 153) !important]复制代码
3.2、LocalAI 的部署
- git clone https://github.com/go-skynet/LocalAI
- cd LocalAI
- docker compose up -d –pull always
[color=rgb(51, 102, 153) !important]复制代码
- curl http://localhost:8080/models/apply
- -H “Content-Type: application/json”
- -d ‘{ “id”: “model-gallery@bert-embeddings” }’
- curl http://localhost:8080/v1/embeddings
- -H “Content-Type: application/json”
- -d ‘{ “input”: “The food was delicious and the waiter…”,
- “model”: “bert-embeddings” }’
- {
- “created”: 1702050873,
- “object”: “list”,
- “id”: “b11eba4b-d65f-46e1-8b50-38d3251e3b52”,
- “model”: “bert-embeddings”,
- “data”: [
- {
- “embedding”: [
- -0.043848168,
- 0.067443006,
- …
- 0.03223838,
- 0.013112408,
- 0.06982294,
- -0.017132297,
- -0.05828256
- ],
- “index”: 0,
- “object”: “embedding”
- }
- ],
- “usage”: {
- “prompt_tokens”: 0,
- “completion_tokens”: 0,
- “total_tokens”: 0
- }
- }
[color=rgb(51, 102, 153) !important]复制代码
- curl http://localhost:8080/models/apply
- -H “Content-Type: application/json”
- -d ‘{ “id”: “huggingface@thebloke__zephyr-7b-beta-gguf__zephyr-7b-beta.q4_k_s.gguf”,
- “name”: “zephyr-7b-beta” }’
- curl http://localhost:8080/v1/chat/completions
- -H “Content-Type: application/json”
- -d ‘{ “model”: “zephyr-7b-beta”,
- “messages”: [{
- “role”: “user”,
- “content”: “Why is the Earth round?”}],
- “temperature”: 0.9 }’
- {
- “created”: 1702050808,
- “object”: “chat.completion”,
- “id”: “67620f7e-0bc0-4402-9a21-878e4c4035ce”,
- “model”: “thebloke__zephyr-7b-beta-gguf__zephyr-7b-beta.q4_k_s.gguf”,
- “choices”: [
- {
- “index”: 0,
- “finish_reason”: “stop”,
- “message”: {
- “role”: “assistant”,
- “content”: “\nThe Earth appears round because it is
- actually a spherical body. This shape is a result of the
- gravitational forces acting upon it from all directions. The force
- of gravity pulls matter towards the center of the Earth, causing
- it to become more compact and round in shape. Additionally, the
- Earth’s rotation causes it to bulge slightly at the equator,
- further contributing to its roundness. While the Earth may appear
- flat from a distance, up close it is clear that our planet is
- indeed round.”
- }
- }
- ],
- “usage”: {
- “prompt_tokens”: 0,
- “completion_tokens”: 0,
- “total_tokens”: 0
- }
- }
[color=rgb(51, 102, 153) !important]复制代码
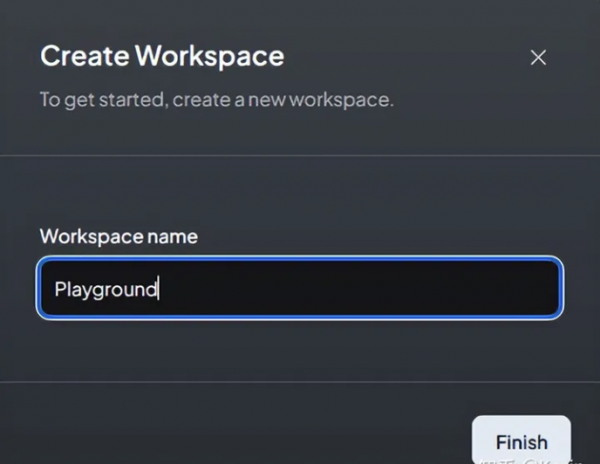
3.3、部署和配置 AnythingLLM
- docker pull mintplexlabs/anythingllm:master
- export STORAGE_LOCATION=”/var/lib/anythingllm” && \
- mkdir -p $STORAGE_LOCATION && \
- touch “$STORAGE_LOCATION/.env” && \
- docker run -d -p 3001:3001 \
- -v ${STORAGE_LOCATION}:/app/server/storage \
- -v ${STORAGE_LOCATION}/.env:/app/server/.env \
- -e STORAGE_DIR=”/app/server/storage” \
- mintplexlabs/anythingllm:master
[color=rgb(51, 102, 153) !important]复制代码

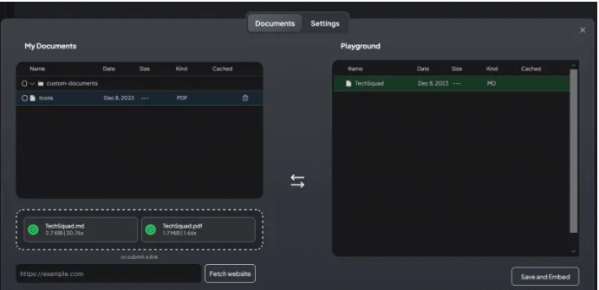
- Adding new vectorized document into namespace playground
- Chunks created from document: 4
- Inserting vectorized chunks into Chroma collection.
- Caching vectorized results of custom-documents/techsquad-3163747c-a2e1-459c-92e4-b9ec8a6de366.json to prevent duplicated embedding.
- Adding new vectorized document into namespace playground
- Chunks created from document: 8
- Inserting vectorized chunks into Chroma collection.
- Caching vectorized results of custom-documents/techsquad-f8dfa1c0-82d3-48c3-bac4-ceb2693a0fa8.json to prevent duplicated embedding.
[color=rgb(51, 102, 153) !important]复制代码
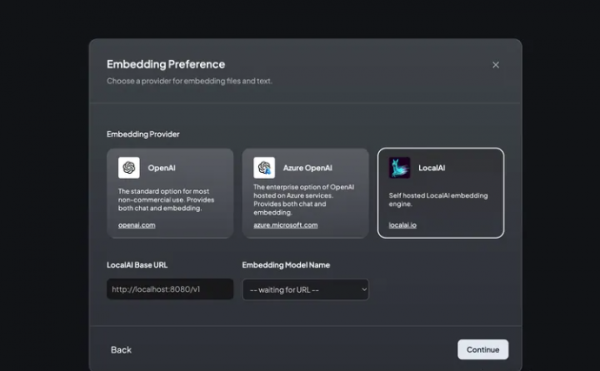
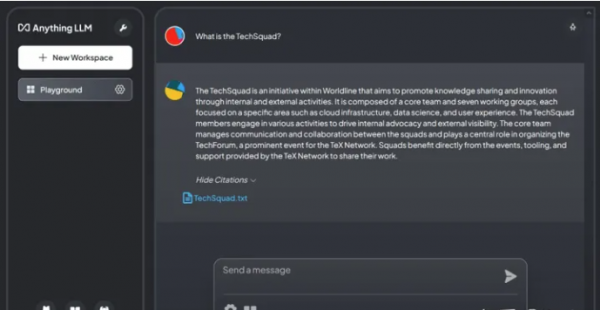 AnythingLLM 的一个有趣功能是它能够显示构成其响应基础的内容。
AnythingLLM 的一个有趣功能是它能够显示构成其响应基础的内容。

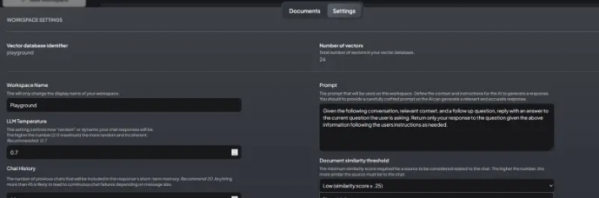
3.4、安装和配置 Vector Admin
- git clone https://github.com/Mintplex-Labs/vector-admin.git
- cd vector-admin/docker/
- cp .env.example .env
[color=rgb(51, 102, 153) !important]复制代码
- SERVER_PORT=3002
- DATABASE_CONNECTION_STRING=”postgresql://vectoradmin:password@127.0.0.1:5433/vdbms”
[color=rgb(51, 102, 153) !important]复制代码
- cd ../frontend/
- cp .env.example .env.production
[color=rgb(51, 102, 153) !important]复制代码
- GENERATE_SOURCEMAP=false
- VITE_API_BASE=”http://127.0.0.1:3002/api”
[color=rgb(51, 102, 153) !important]复制代码
- docker compose up -d –build vector-admin
[color=rgb(51, 102, 153) !important]复制代码
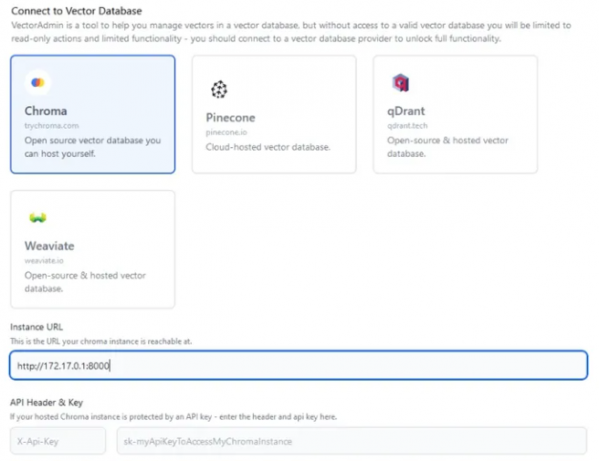
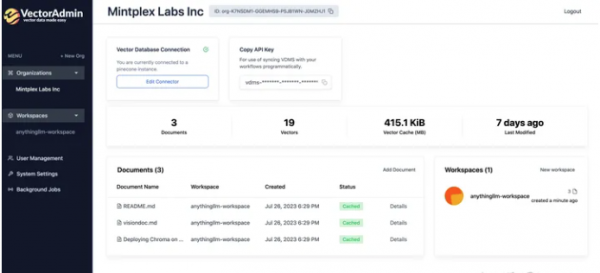
四、总结
五、References
1.本站资源都是白菜价出售,同样的东西,我们不卖几百,也不卖几十,甚至才卖几块钱,一个永久会员能下载全站100%源码了,所以单独购买也好,会员也好均不提供相关技术服务。
2.如果源码下载地址失效请联系站长QQ进行补发。
3.本站所有资源仅用于学习及研究使用,请必须在24小时内删除所下载资源,切勿用于商业用途,否则由此引发的法律纠纷及连带责任本站和发布者概不承担。资源除标明原创外均来自网络整理,版权归原作者或本站特约原创作者所有,如侵犯到您权益请联系本站删除!
4.本站站内提供的所有可下载资源(软件等等)本站保证未做任何负面改动(不包含修复bug和完善功能等正面优化或二次开发);但本网站不能保证资源的准确性、安全性和完整性,由于源码具有复制性,一经售出,概不退换。用户下载后自行斟酌,我们以交流学习为目的,并不是所有的源码都100%无错或无bug;同时本站用户必须明白,【安安资源网】对提供下载的软件等不拥有任何权利(本站原创和特约原创作者除外),其版权归该资源的合法拥有者所有。
5.请您认真阅读上述内容,购买即以为着您同意上述内容,由于源码具有复制性,一经售出,概不退换。
安安资源网 » AnythingLLM:基于RAG方案构专属私有知识库(开源|高效|可定制)
![[单机游戏] [模拟养成] 植物大战僵尸中国版](http://www.net188.com/data/attachment/forum/202403/01/133103xg8jh6gfb5tmeebj.jpg.thumb.jpg)



